MySQL5.7 JSON调研报告
MySQL5.7支持对JSON数据的存储,存储时会检查JSON的合法性,不合法插入会失败。
示例:1
2
3
4
5
6
7
8
9mysql> CREATE TABLE t1 (jdoc JSON);
Query OK, 0 rows affected (0.20 sec)
mysql> INSERT INTO t1 VALUES('{"key1": "value1", "key2": "value2"}');
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO t1 VALUES('[1, 2,');
ERROR 3140 (22032) at line 2: Invalid JSON text:
"Invalid value." at position 6 in value (or column) '[1, 2,'.
#JSON常用函数
| 函数名 | 描述 | 示例 | 更多 |
|---|---|---|---|
| JSON_TYPE() | 返回JSON值的类型 | mysql> SELECT JSON_TYPE(‘[“a”, “b”, 1]’); ARRAY |
参考文档 |
| JSON_ARRAY() | 转化输入为JSON数组 | SELECT JSON_ARRAY(‘a’, 1, NOW()); [“a”, 1, “2015-07-27 09:43:47.000000”] |
参考文档 |
| JSON_OBJECT() | 将输入值转换为JSON对象 | SELECT JSON_OBJECT(‘key1’, 1, ‘key2’, ‘abc’); {“key1”: 1, “key2”: “abc”} |
|
| JSON_MERGE() | 将两个或多个JSON组合为一个 | SELECT JSON_MERGE(‘[“a”, 1]’, ‘{“key”: “value”}’); [“a”, 1, {“key”: “value”}] |
参考文档 |
| JSON_EXTRACT() | 传入JSON doc和path,返回对应path的值 | SELECT JSON_EXTRACT(‘[10, 20, [30, 40]]’, ‘$[1]’, ‘$[0]’); [20, 10] |
参考文档 在MySQL5.7.9之后,可以使用→代替此函数 JSON_EXTRACT(column, path)等价于cloumn->path |
| JSON_SET() | 传入(doc,path1,val1,path2,val2,…) 将对应key设置为val(replace and insert) |
SET @j = ‘{ “a”: 1, “b”: [2, 3]}’; SELECT JSON_SET(@j, ‘$.a’, 10, ‘$.c’, ‘[true, false]’); {“a”: 10, “b”: [2, 3], “c”: “[true, false]”} |
参考文档 |
| JSON_INSERT() | 传入(doc,path1,val1,path2,val2,…) 如果key存在,不操作; key不存在,添加对应key和val |
SET @j = ‘{ “a”: 1, “b”: [2, 3]}’; SELECT JSON_INSERT(@j, ‘$.a’, 10, ‘$.c’, ‘[true, false]’); {“a”: 1, “b”: [2, 3], “c”: “[true, false]”} |
参考文档 |
| JSON_REPLACE() | 传入(doc,path1,val1,path2,val2,…) 只替换key,不添加新的key |
SET @j = ‘{ “a”: 1, “b”: [2, 3]}’; SELECT JSON_REPLACE(@j, ‘$.a’, 10, ‘$.c’, ‘[true, false]’); {“a”: 10, “b”: [2, 3]} |
参考文档 |
JSON访问
{ “a”: [ [ 3, 2 ], [ { “c” : “d” }, 1 ] ], “b”: { “c” : 6 }, “one potato”: 7, “b.c” : 8 }
$.a[1] 获取的值为 [ { “c” : “d” }, 1 ]
$.b.c 获取的值为 6
$.”b.c” 获取的值为 8
对比上面最后两个例子,可以看到用引号包围的表达式会被当作一个字符串键值。
单个星号*表示匹配某个JSON对象中所有的成员
[ * ]表示匹配某个JSON数组中的所有元素
prefix**suffix表示所有以prefix开始,以suffix结尾的路径
两个连着星号**不能作为表达式的结尾,不能出现连续的三个星号***
JSON索引
MySQL不支持直接在JSON列上建索引。如果想建立索引可以首先对感兴趣的JSON键建立虚拟列,然后对虚拟列建立索引。
示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47mysql> CREATE TABLE jemp (
-> c JSON,
-> g INT GENERATED ALWAYS AS (c->"$.id"),
-> INDEX i (g)
-> );
Query OK, 0 rows affected (0.28 sec)
mysql> INSERT INTO jemp (c) VALUES
> ('{"id": "1", "name": "Fred"}'), ('{"id": "2", "name": "Wilma"}'),
> ('{"id": "3", "name": "Barney"}'), ('{"id": "4", "name": "Betty"}');
Query OK, 4 rows affected (0.04 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> SELECT c->>"$.name" AS name
> FROM jemp WHERE g > 2;
+--------+
| name |
+--------+
| Barney |
| Betty |
+--------+
2 rows in set (0.00 sec)
mysql> EXPLAIN SELECT c->>"$.name" AS name
> FROM jemp WHERE g > 2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: jemp
partitions: NULL
type: range
possible_keys: i
key: i
key_len: 5
ref: NULL
rows: 2
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Note
Code: 1003
Message: /* select#1 */ select json_unquote(json_extract(`test`.`jemp`.`c`,'$.name'))
AS `name` from `test`.`jemp` where (`test`.`jemp`.`g` > 2)
1 row in set (0.00 sec)
建表后增加索引:1
2
3
4
5
6
7CREATE TABLE features (
id INT NOT NULL AUTO_INCREMENT,
feature JSON NOT NULL,
PRIMARY KEY (id)
);
ALTER TABLE features ADD feature_street VARCHAR(30) AS (JSON_UNQUOTE(feature->"$.properties.STREET"));
ALTER TABLE features ADD INDEX (feature_street);
JSON存储结构
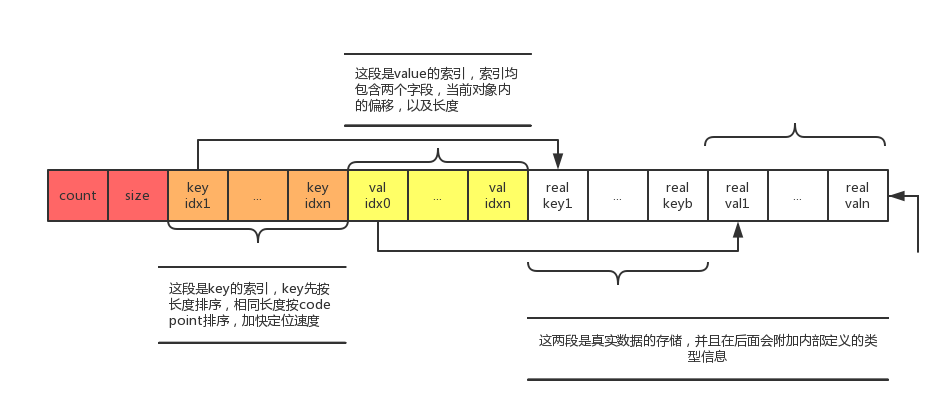
JSON文档本身是层次化的结构,因而MySQL对JSON存储也是层次化的。对于每一级对象,存储的最前面为存放当前对象的元素个数,以及整体占的大小。需要注意的是:
- JSON对象的Key索引(图中橙色部分)都是排序好的,先按长度排序,长度相同的按照code point排序;Value索引(图中黄色部分)根据对应的Key的位置依次排列,最后面真实的数据存储(图中白色部分)也是如此
- Key和Value的索引对存储了对象内的偏移和大小,单个索引的大小固定,可以通过简单的算术跳转到距离为N的索引
- 通过MySQL5.7.16源代码可以看到,在序列化JSON文档时,MySQL会动态检测单个对象的大小,如果小于64KB使用两个字节的偏移量,否则使用四个字节的偏移量,以节省空间。同时,动态检查单个对象是否是大对象,会造成对大对象进行两次解析,源代码中也指出这是以后需要优化的点
- 现在受索引中偏移量和存储大小四个字节大小的限制,单个JSON文档的大小不能超过4G;单个KEY的大小不能超过两个字节,即64K
- 索引存储对象内的偏移是为了方便移动,如果某个键值被改动,只用修改受影响对象整体的偏移量
- 索引的大小现在是冗余信息,因为通过相邻偏移可以简单的得到存储大小,主要是为了应对变长JSON对象值更新,如果长度变小,JSON文档整体都不用移动,只需要当前对象修改大小
- 现在MySQL对于变长大小的值没有预留额外的空间,也就是说如果该值的长度变大,后面的存储都要受到影响
- 结合JSON的路径表达式可以知道,JSON的搜索操作只用反序列化路径上涉及到的元素,速度非常快,实现了读操作的高性能
- 不过,MySQL对于大型文档的变长键值的更新操作可能会变慢,可能并不适合写密集的需求
其他
参考链接:
官方文档
MySQL 5.7 JSON 实现简介
JSON的比较和排序以及字符串转义暂时没有调研。